이 논문은 ICLR 2019에 accept된 논문으로, 그동안 논문들에서 당연하게 믿어져왔던 신념 두가지을 여러 모델과 실험을 통해 반박하고, 그 이유를 추측하는 논문이다.
여기서 두가지 신념이란
1. 매우 크고, over-parameterized된 모델을 사용하여 학습을 먼저 진행하는 것이 중요하다.
2. pruned된 구조와 그 weights이 최종 효율적인 모델을 생산해내는데 필수적이다.
이 논문에서는 이 두 신념을 반박하기 위해 "처음부터 작은 모델로, weight를 새롭에 initialize해서 학습"해서 더 좋은 성능이 나온 결과들을 제시했다.
Pruning은 가지치기할 대상에 따라 Structure, Unstructure Pruning으로 분류가 되는데, 이번 논문에서는 Structure Pruning 알고리즘 모델들을 중심으로 실험을 진행했다.


이 논문에서는 아래와 같이 크게 3 종류의 Pruning 기법들을 사용하여 실험을 진행했고, 새로운 가설을 제시한 "Lottery Hypothesis"와 상반된 가설이 나온 이유를 설명했다.
1. PREDEFINED PRUNING METHODS: Pruning ratio를 사람이 결정.
2. AUTOMATIC STRUCTURED PRUNING METHODS: Pruning ratio를 algorithm이 결정.
3. UNSTRUCTURED METHOD
---
Experiments에서 사용한 각 방법들의 간략한 설명과 실험결과들을 보여줬다. 실험표에서 등장하는 Scratch-E, Scratch-B는 각각 E-> 기존 모델 학습 epoch / B -> 기존 모델 학습과 동일한 계산량의 epoch (예를 들어 계산량이 기존에 비해 2배 줄었다면 epoch을 2배 늘린다.)로 학습한 모델이다.
논문에 작성된 실험결과들을 보면 Predefined, Automatic 모두 Scratch-B에서 기존 Fine-Tuning 모델들보다 좋은 성능을 보여주는 것을 통해 기존 신념이 올바르지 않다는 것을 보여준다.
하지만 Unstructured Pruning 기법들은 작은 데이터셋(CIFAR)에서도 Fine-tuned 모델이 가장 좋은 결과가 많이 나왔으며, 큰 데이터셋(ImageNet)에서는 4개의 결과 중 3개의 실험에서 Fine-tuned 모델이 최고의 성능을 보여주었다.
이에 대해서
CIFAR -> 매우 SPARSE한 네트워크일 경우 학습이 어렵다.
IMAGENET -> 데이터셋 그자체의 크기/복잡도가 높다.
혹은
Unstructured Pruning은 Structure과 다르게 weight distribution이 상당히 변하게된 것도 성능 하락의 이유일 수도 있다고 했다.
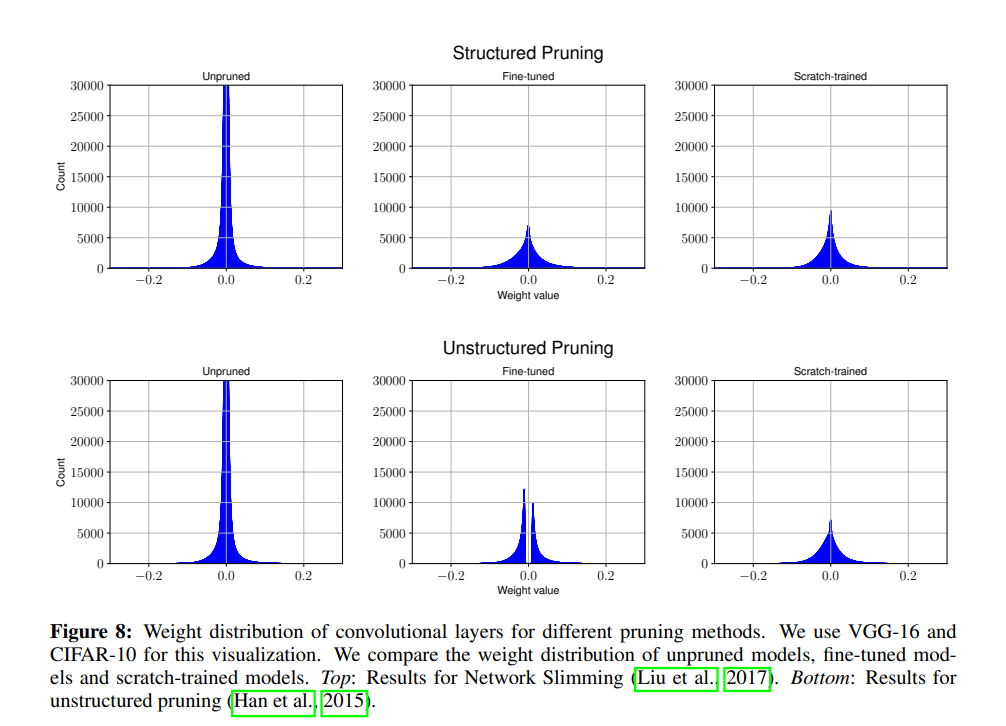
위 그림이 두 Pruning 기법에 대한 weight value distribution인데, 확실히 fine-tuned 부분에 차이를 볼 수 있다.
Network Pruning as Architecture Search
위의 연구를 통해서 Pruned Network의 weight이 그리 중요하지 않다는 점을 밝혔다. 그렇다면, Network Pruning으로 efficient architecture을 찾아내고, 처음부터 학습시키는 것이 더 효율적일 것이다. 그래서 이 논문은
pruning-obtained model과 uniformly pruned model을 비교하면서 network pruning의 architecture search 능력을 평가하였다.
Pruning-Obtained Model로 Network Slimming과 Unstructured Pruning을 활용한 모델을 사용했고, uniformly pruned model로 naive predefined pruning strategy를 활용했다.
실험 결과, Pruning-Obtained model이 더 좋은 효율을 보여주었다. 그러나 이 결과는 VGG 모델에서만 일관된 결과를 보여주었다.
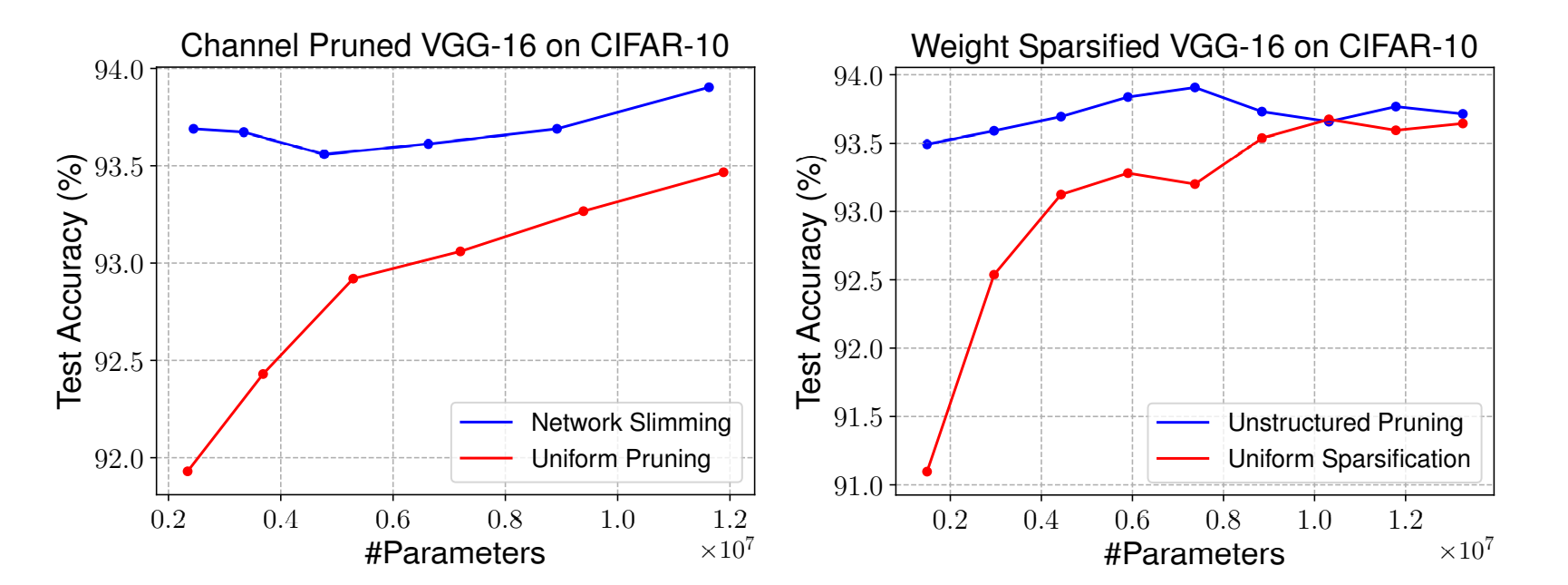
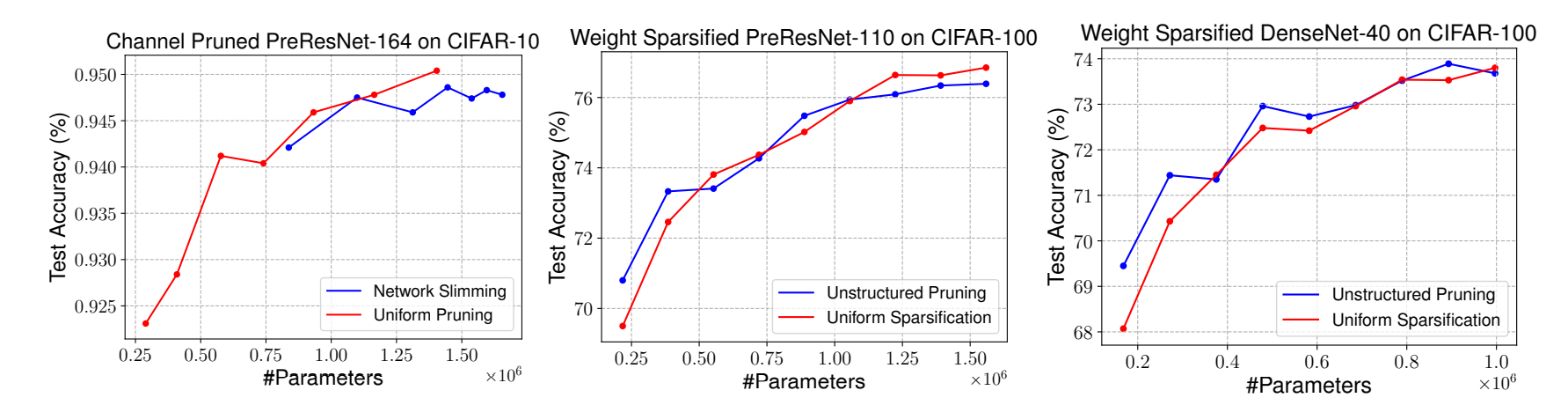
VGGNet의 pruned model은 여러번 실험했을 때 일관적인 패턴을 보여주었다. 또한 각 layer마다 prune ratio에 차이가 있다는 것을 관찰했다( VGG는 뒤쪽 stage(layer)로 갈수록 더욱 redundancy하다.)
그와 반대로, PreResNet, DenseNet에서는 모든 layer에서 prune ratio가 거의 동일한 결과를 얻었다. 이러한 이유때문에 Uniform Pruning model(각 layer마다 몇 %를 pruning할지 미리 결정된 모델)이 더 좋은 성능을 얻었다고 판단한다.
이 실험을 통해 얻은 pruned VGG model의 특성(average number of channels in each layer stage)을 활용해 pruning을 하는 Guided Pruning으로 VGGNet을 Pruning 한 결과, 더 좋은 성능을 보여주었다. cifar10을 사용한 vgg pruned model의 pattern을 증류(distill)하여 cifar-100에 적용한 모델(갈색)은 guided pruning보단 성능이 낮았지만 기존 uniform pruning 보단 성은이 좋았다.
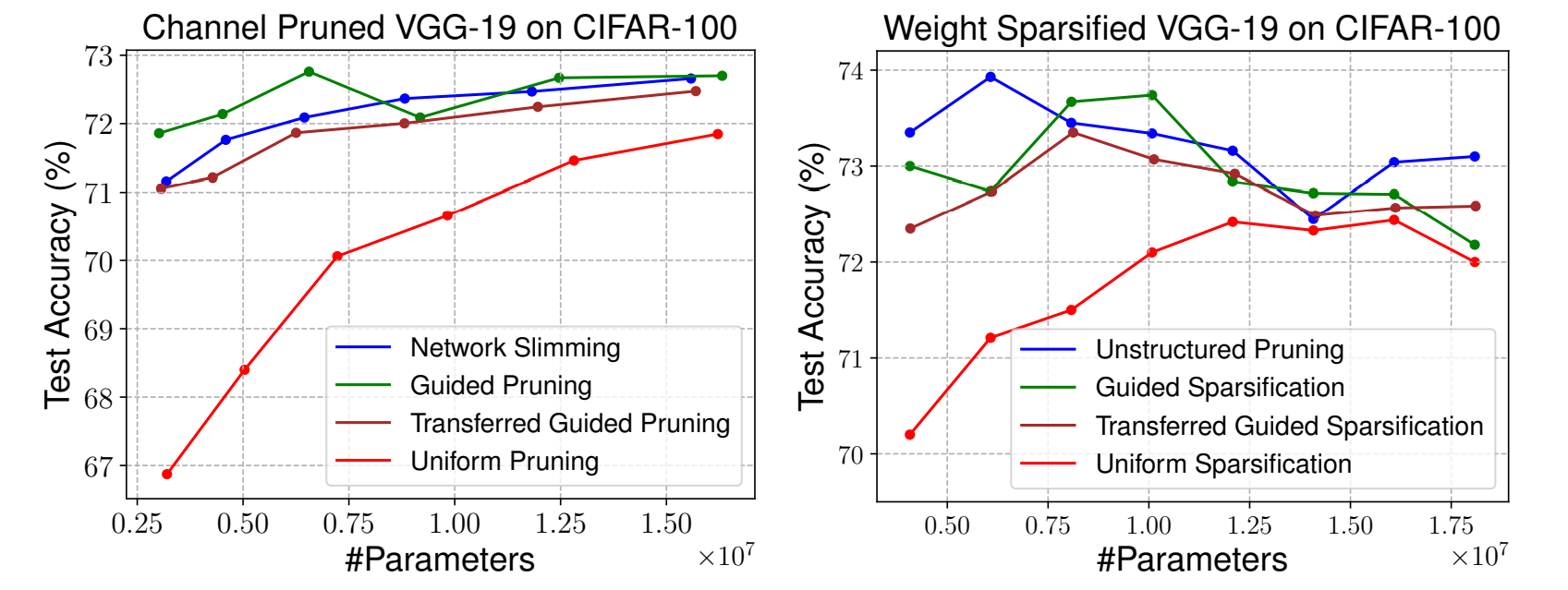
저자들은 pruning을 architecture search로 사용하는 방법은 one-pass training만 필요하다는 장점과, sub-networks으로만 serach space가 준다는 단점을 가지고 있다고 설명했다.
cf) 기존 NAS와 같은 architecture search 기법들은 activation functions와 different layer orders도 search space에 포함된다.
Experiments on the LOTTERY TICKET HYPOTHESIS
Lottery 가설은 sub-network를 reinitialize했을 때 성능이 하락한다 했고, 이는 본 논문과 상반된 결론이다.
이에 대해 저자는 Lottery 논문의 실험들은 layer가 적은 모델에서만 실험이 진행되었고, learning rate도 낮게 설정되어 있고, unstructure pruning에서만 winning ticket들의 성능이 향상되었다고 한다.

-----
아래는 본 논문에서 각 방법에 따라 사용한 모델들입니다.
이 논문이 2019년에 나온 논문이니 많은 structure pruning 논문 중 아래 논문들을 우선적으로 보는 것도 좋을 것 같습니다.
1. PREDEFINED PRUNING METHODS: Pruning ratio를 사람이 결정.
- Pruning filters for efficient convnets. In ICLR, 2017.
- Thinet: A filter level pruning method for deep neural network compression. In ICCV, 2017
- Channel pruning for accelerating very deep neural networks. In ICCV, 2017b
- Soft filter pruning for accelerating deep convolutional neural networks. In IJCAI, 2018a
2. AUTOMATIC STRUCTURED PRUNING METHODS: Pruning ratio를 algorithm이 결정.
- Learning efficient convolutional networks through network slimming. In ICCV, 2017
- Data-driven sparse structure selection for deep neural networks. ECCV, 2018
3. UNSTRUCTURED METHOD
EXTRA. HYPOTHESIS
'Machine Learning > Pruning-가지치기' 카테고리의 다른 글
| Pruning 논문 리뷰 리스트 (0) | 2021.08.10 |
|---|---|
| [논문 리뷰] Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration (0) | 2021.05.21 |
