github에서 pytorch 코드를 살펴보다 보면, apex, amp가 사용되는 모습을 자주 볼 수 있다.
amp는 Automatic Mixed Precision의 약자로, 몇 operations들에서 float16 데이터타입을 사용해 학 속도를 향상시켜주는 방법을 제공해준다. 기존 pytorch는 데이터타입이 float32로 기본 설정이라는 것도 참고하면 좋을 것 같다.
또한 구글링을 하다보면 amp를 사용하는 방법이 apex.amp 와 torch.cuda.amp 두 방법이 나오는데, 아래 포스트를 보면 apex의 implementation들이 Pytorch에서 지원을 시작해서, apex는 이제 앞으로는 사용되지 않을 것이라고 한다.
https://discuss.pytorch.org/t/torch-cuda-amp-vs-nvidia-apex/74994/3
AMP를 사용하기 위해선 두가지를 알고 있어야 한다.
1. Autocasting
2. Gradient Scaling
추가적으로 pytorch의 어떤 operation들이 float16연산을 지원하는지를 알고있어야 한다.
1. Autocasting
autocasting은 context manager나 decorator로 사용될 수 있다.
torch.autocast(device_type, dtype=None, enabled=True, cache_enabled=None)
torch.cuda.amp.autocast(enabled=True, dtype=torch.float16, cache_enabled=True)See torch.autocast. torch.cuda.amp.autocast(args...) is equivalent to torch.autocast("cuda", args...)
1-1. context manager의 경우
# 1-1. Context manager
with torch.cuda.amp.autocast():
output = model(input)
loss = loss_fn(output,target)위 영역에서 autocasting을 할때 모델의 파라미터나 입력 데이터의 데이터타입을 half()를 사용하여 변경하지 않고 그대로 넣어도 자동적으로 precision을 mixing해준다.
권고사항
autocast는 network에서의 loss 계산과 forward pass만 사용하길 권장한다.
backward passes는 추천하지 않는다.
아래 포스트에서 각 operation들이 어떤 데이터 타입(float16 vs float32)로 autocast되는지 확인하길 추천한다.
https://pytorch.org/docs/stable/amp.html#autocast-op-reference
Automatic Mixed Precision package - torch.cuda.amp — PyTorch 1.11.0 documentation
The following lists describe the behavior of eligible ops in autocast-enabled regions. These ops always go through autocasting whether they are invoked as part of a torch.nn.Module, as a function, or as a torch.Tensor method. If functions are exposed in mu
pytorch.org
1-2. decorator의 경우
# 1-2. decorator
class AutocastModel(nn.Module):
@torch.cuda.amp.autocast()
def forward(self, input):
...위처럼 사용될 수 있다.
2. Gradient Scaling
만약 forward pass가 float16으로 계산된다면, backward pass또한 float16의 gradients를 생산해낼것이다. 작은 크기의 gradient들은 float16으로는 표현하기에 적합하지 않을 수 있다. 즉 0으로 flush될 수 있다.
이를 막기 위해, gradient scaling가 network의 loss에 scale factor를 곱해줌으로써 backward pass를 위한 scaled loss를 만들어준다. 이는 0으로 flush 되는 것을 막아준다.
이러한 방법은 각 파라미터들의 gradient가 optimizer가 파라미터를 update하기 전에 unscaled 되기 때문에, scale factor가 learning rate을 방해하는 일은 일어나지 않는다.
scaler = torch.cuda.amp.GradScaler()
...
scaler.scale(loss).backward()
# scaler.unscale_(optimizer)
# torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
scaler.step(optimizer)
scaler.update()scaler을 선언해준 후, scaler.scale(loss).backward()을 통해 backward pass 계산을 한다.
scaler.step(optimizer)을 통해 unscale을 해주고, inf/NaN gradient가 발견되지 않으면 optimizer.step()을 해준다. 만약 발견되면 params가 corrupt되는 것을 막기 위해 optimizer.step()이 skip된다고 한다. 만약 optimizer step이 skip이 되면 이를 방지하고자 scale에 backoff_factor를 곱해준다.
참고
unscale은 step에서 자동적으로 되지만, 만약 step이전에 해주어야 할 이유가 있다면 unscale함수를 통해 직접 unscale해줄 수 있다.
참고 코드
테스트용 코드의 일부분을 첨부한다. 전체 코드는 깃허브에 올려놓았다.
for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
input = input.cuda()
target = target.cuda()
with torch.cuda.amp.autocast():
output = model(input)
loss = criterion(output, target)
# output = model(input)
# loss = criterion(output, target)
# measure accuracy and record loss
err1, err5 = accuracy(output.data, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(err1.item(), input.size(0))
top5.update(err5.item(), input.size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
# loss.backward()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
# scaler.unscale_(optimizer)https://github.com/dbwp031/Accel_pytorch
GitHub - dbwp031/Accel_pytorch: Accelerating tools for Pytorch (AMP, DDP ...)
Accelerating tools for Pytorch (AMP, DDP ...). Contribute to dbwp031/Accel_pytorch development by creating an account on GitHub.
github.com
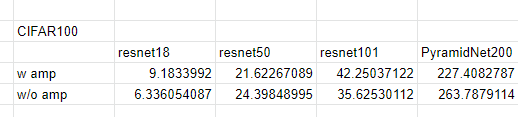
실험 결과
V100 1기로 다음과 같이 성능을 테스트했을때, 작은 모델에서는 amp를 사용하지 않았을 때 더 좋은 성능이 나온 적도 있었지만, 가장 큰 모델인 PyramidNet200에서 성능을 테스트했을 때엔 amp를 사용했을 때 확실히 좋은 성능을 보여주었다. 따라서 ImageNet 모델 학습에서도 도움이 될 것으로 판단된다.
'Pytorch > 가속화' 카테고리의 다른 글
| [Pytorch] DDP-Distributed Data Parallel 구현 (1) | 2022.03.20 |
|---|
